|
|
前面几篇中已经讲述过,如果使用MCTS及其变种实现斗地主AI,链结可参考:
这期聊一聊目前采用卷积神经网络(CNN)实现斗地主AI的方案。
卷积神经网络
介绍一下卷积神经网络,个人觉得下面几篇文章讲得比较清楚了,有需要请参考:
卷积神经网络的斗地主模型
这里只讨论打牌过程的CNN网络,对于叫地主和加倍部分,可以参考《棋牌AI》专栏中的文章。
打牌过程使用两个CNN网络,包括策略选择网络和带牌选择网络。策略选择网络,先确定出牌类型而不具体展开确定具体带牌;带牌选择网络最终确定带什么牌。之所以把带牌选择单独拿出来做,主要是基于两方面考虑:
- 斗地主的动作空间有13551种,导致训练策略选择网络不够精确。
- 监督学习的训练数据中,很难完全覆盖13551种动作的情况。比如666777888999带4单或带4对
策略选择网络
根据当前已知的牌局信息,通过监督学习的方式,训练得出行动集合的概率分布。
输入(牌局状态)
做棋牌游戏的朋友应该对游戏录像不陌生。每一步行动可以看作视频的一帧,人类玩家依赖的决策信息,就是这些帧,越是高级的人类玩家,能准确记忆的帧就越多。通过这些已知信息,猜测对手剩余的手牌,并以此进行出牌推演从而作出最大化自身利益的行动。
为了学习人类玩家的打法,需要尽量还原人类玩家做决策时已知的牌局信息。比如,自己手牌,未现的牌,自己的角色,对手剩余的手牌,从开局到当前所有的对局过程(谁出了什么牌,谁跟了什么牌,谁不要之类),以此确定x-轴和y-轴的含义:
- X轴,表示从3到大王的15张牌,分别为3,4,5,6,7,8,9,10,J,Q,K,A,2,SJ,BJ
- Y轴,表示每种牌的张数,可能构成的牌型以及角色、轮数、每个玩家剩余手牌数这类信息
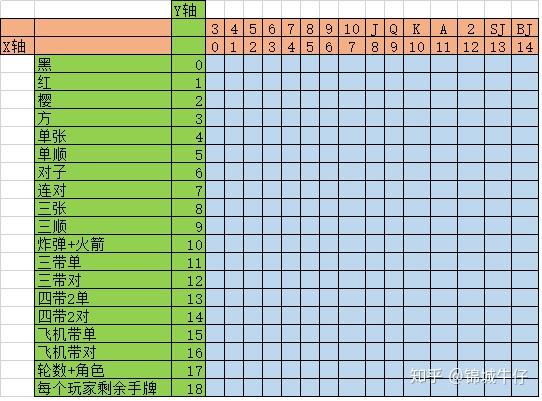
注,y轴的含义和具体结构仅供参考
从地主开始每人行动一次作为一轮(round),每场斗地主游戏的轮数是不确定的,为尽量还原已知信息,选择当前状态向前6轮内的行动作为决策参考范围。按照由近到远的顺序构建牌局状态(X-轴):
- 自己的手牌
- 未现的牌(类似计牌器中的内容)
- 上个行动的出牌,角色,轮数和剩余手牌
- 上上个行动的出牌,角色,轮数和剩余手牌
- 。。。。。一直往上回溯六轮:行动的出牌,角色,轮数和剩余手牌
- 六轮之前已经打出的牌
输出(行动的概率分布)
策略选择网络的输出就是斗地主出牌的所有可能行动的概率分布,但是只确定出牌类型,不确定带牌。比如,单张从3到大王,共15种;对子,从33到22共13种,详细如下表。
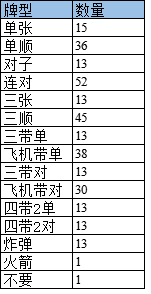
具体的输出就是309个概率值分别按顺序对应上面的表,取概率值最大的作为策略输出。
带牌选择网络
在已知带牌类型、主牌信息和剩余牌等信息的情况下,选择要带的牌作为最终的行动输出。比如,手牌是33344457JA,策略选择网络确定出“飞机带单”。这里我们定义333444为主牌,手牌除去333444剩余的牌为待选牌。
输入
同样是使用监督学习的方式,学习人类玩家在选择带牌选择时的权衡和选择。已知信息包括:行动牌型,要带牌的类型(单张或对子),要带牌的长度,主牌,除去主牌后剩余的牌,未现牌,角色,轮数和玩家剩余手牌数量等。
输出
每次只决策一个带牌,如果有多个带牌需要多次调用带牌选择网络。比如,666777带2个单,需要调用再次带牌选择网络。所以,输出为28个(15个单牌,13个对子)概率。这样就确定了最终的行动。
参考链接: |
|



 发表于 2023-3-5 08:10:34
发表于 2023-3-5 08:10:34
